クラウド上の仮想マシンを扱っていると、ディスクの容量を気にしたくないことから、クラウドストレージを利用したいことがあります。最近ですと、Amazon EC2にAmazon S3をマウントして利用したりするでしょう。いろいろな方法がありますが、私が最も簡単だと思う方法を紹介したいと思います。
手順
- S3のバケットを作成
- IAMを作成
- EC2より仮想インスタンスの立ち上げ
- goofysのインストール
- S3のマウント
- テストファイルの書き込み
1. S3のバケットを作成
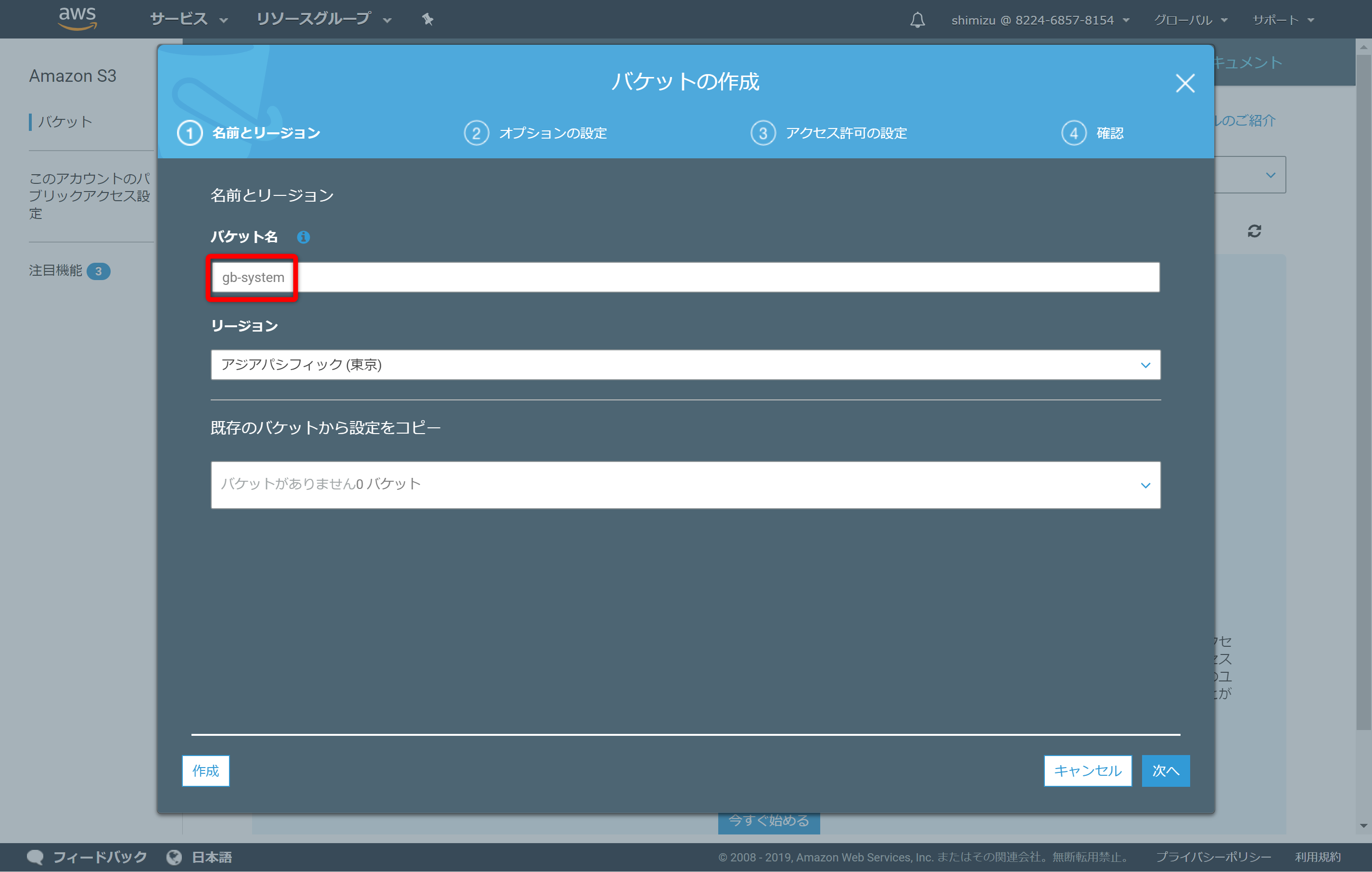
仮想インスタンスにマウントするためのS3バケットを作成します。ここでは「gb-system」バケットを用意しました。特別な設定は必要なくデフォルトで作成して問題ありません。
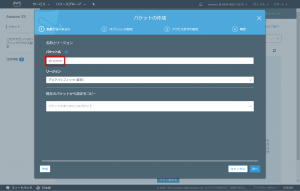
2. IAMを作成
EC2の仮想インスタンスよりS3にアクセスするための権限を用意します。AWS CLIを利用する方法もありますが、特別細かな設定が不要であれば、IAMを利用し直接権限を与えるほうが簡単です。
AWSのコンソールから「IAM」サービスより「ロール」をクリックします。そして「ロールの作成」ボタンをクリックします。
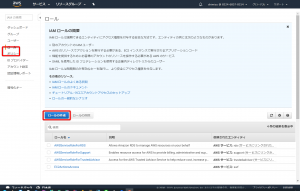
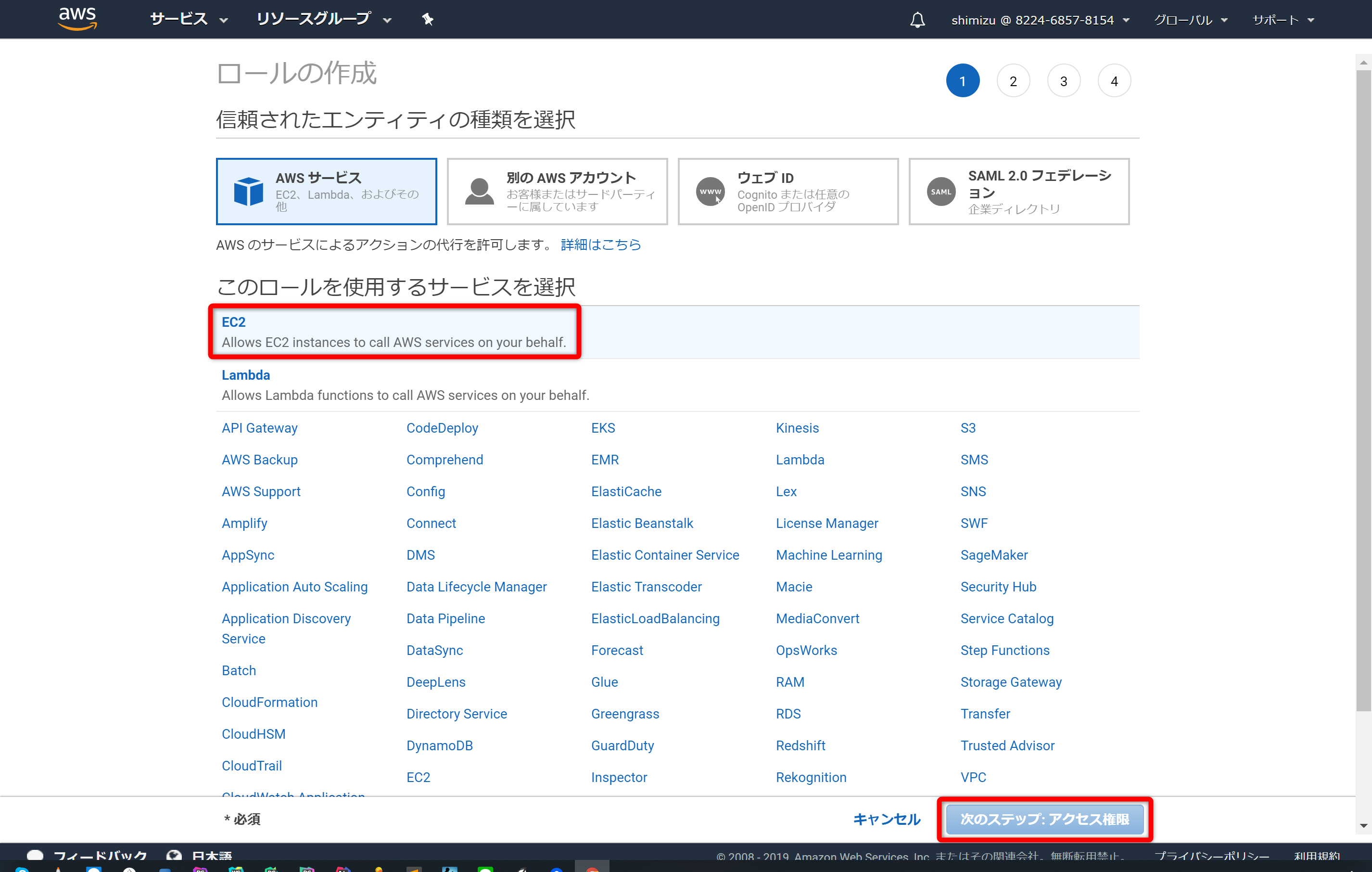
「EC2」を選択し、次のステップへ進みます。
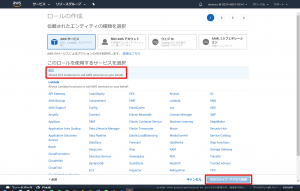
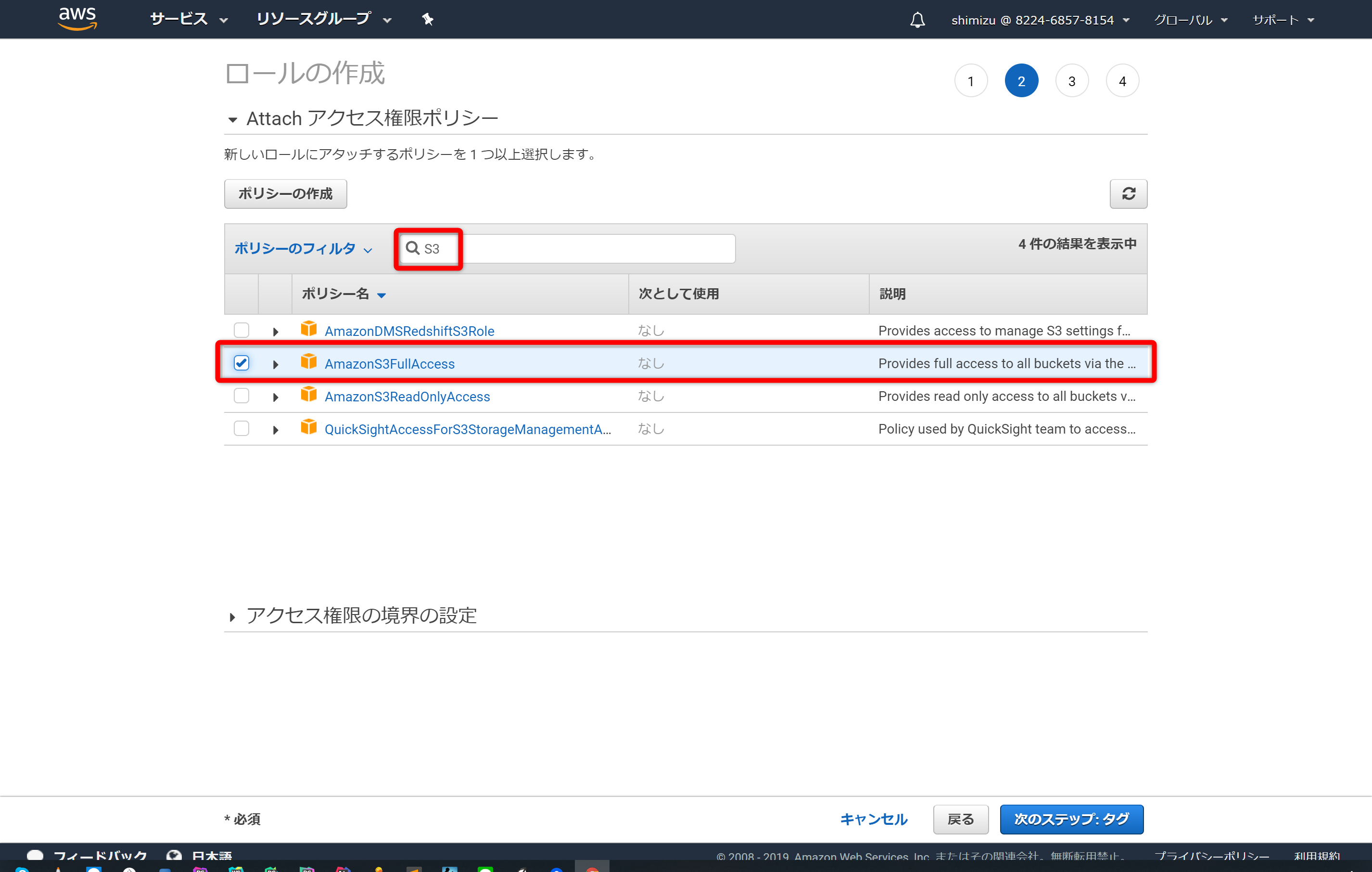
「ポリシーのフィルタ」に「S3」と入力し「AmazonS3FullAccess」を探しチェックを入れます。そして次のステップへ進んで下さい。
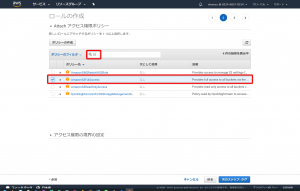
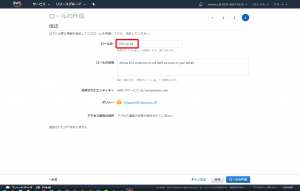
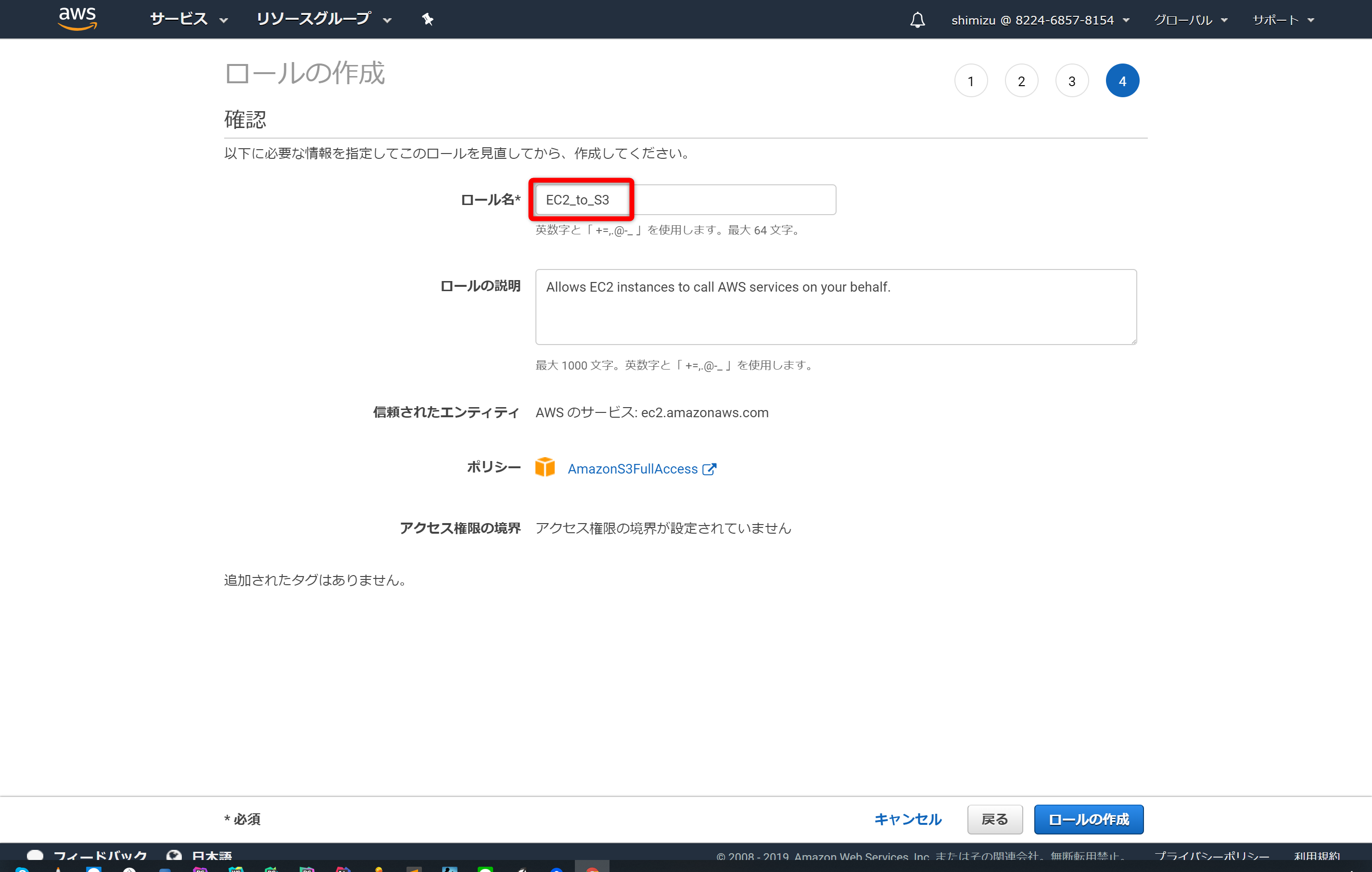
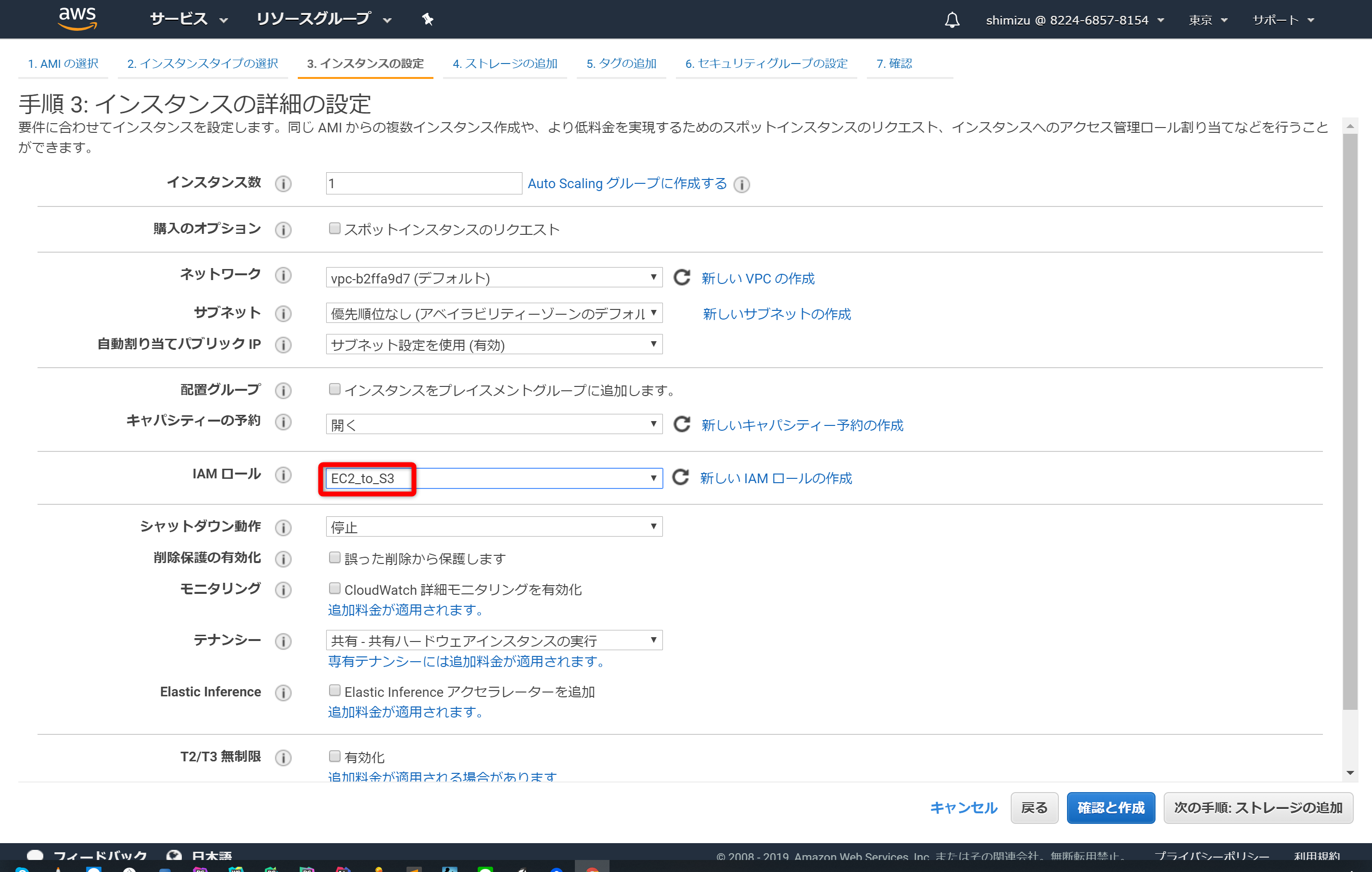
ここではロールの名前を「EC2_to_S3」としました。
3. EC2より仮想インスタンスの立ち上げ
EC2より仮想インスタンスを立ち上げます。今回はAmazon Linux2を利用します。立ち上げる際の注意点は、Step2において「IAMロールの設定」を行うことです。2.で作成したIAMを設定して下さい。それ以外に特別な設定はありません。
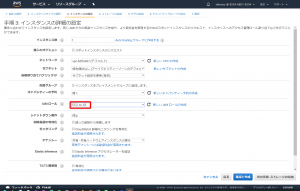
念のため、立ち上げ直後はOSをupdateしておきましょう。
$ sudo yum -y update
4. goofysのインストール
S3をマウントする方法はいくつかありますが、転送速度の観点から個人的にはgoofysがオススメです。このgoofysはGO言語により実装されているため、GO言語のインストールも必要です。またFUSE (Filesystem in Userspace) を利用して仮想ファイルシステムを構築します。
$ sudo yum -y install golang fuse git
次にGOPATHを設定してgoofysをインストールします。
$ export GOPATH=$HOME/go
$ go get github.com/kahing/goofys
$ go install github.com/kahing/goofys
go getに数分掛かりますので、反応がなくても慌てないでください。
5. S3の自動マウント
goofysがインストールできたら、コマンドだけでS3をマウントすることができます。しかし、OS再起動の際は再マウントが必要になるので、最初から再マウントできるように設定しましょう。自動マウント設定の際、ユーザのuid, gidが必要になるので予め確認しておきます。
$ id
uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal)
今回の場合、uid=1000, gid=1000と表示されています。
またマウントするためのディレクトリも作成しましょう。
$ sudo mkdir /mnt/S3
$ sudo chown ec2-user:ec2-user /mnt/S3
では自動マウントのため「/etc/fstab」を編集しましょう。
$ sudo vi /etc/fstab
この末尾に次のように入力して保存して下さい。
(goofys#の後ろは「S3バケット名」です。また –uid, –gidは idコマンドで調べた値に置き換えてください。)
/home/ec2-user/go/bin/goofys#gb-system /mnt/S3 fuse _netdev,allow_other,--file-mode=0666,--uid=1000,--gid=1000 0 0
これで設定は完了です。OSを再起動してみましょう。
$ sudo reboot
起動したらマウントできているか確認します。
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 475M 0 475M 0% /dev
tmpfs 492M 0 492M 0% /dev/shm
tmpfs 492M 400K 492M 1% /run
tmpfs 492M 0 492M 0% /sys/fs/cgroup
/dev/xvda1 8.0G 1.9G 6.2G 24% /
gb-system 1.0P 0 1.0P 0% /mnt/S3
tmpfs 99M 0 99M 0% /run/user/1000
確かにマウントされていますね。容量は1PB (ペタバイト)と記されています。
6. テストファイルの書き込み
ではファイルを書き込んでみましょう。
$ echo 'Hello S3' > /mnt/S3/test.txt
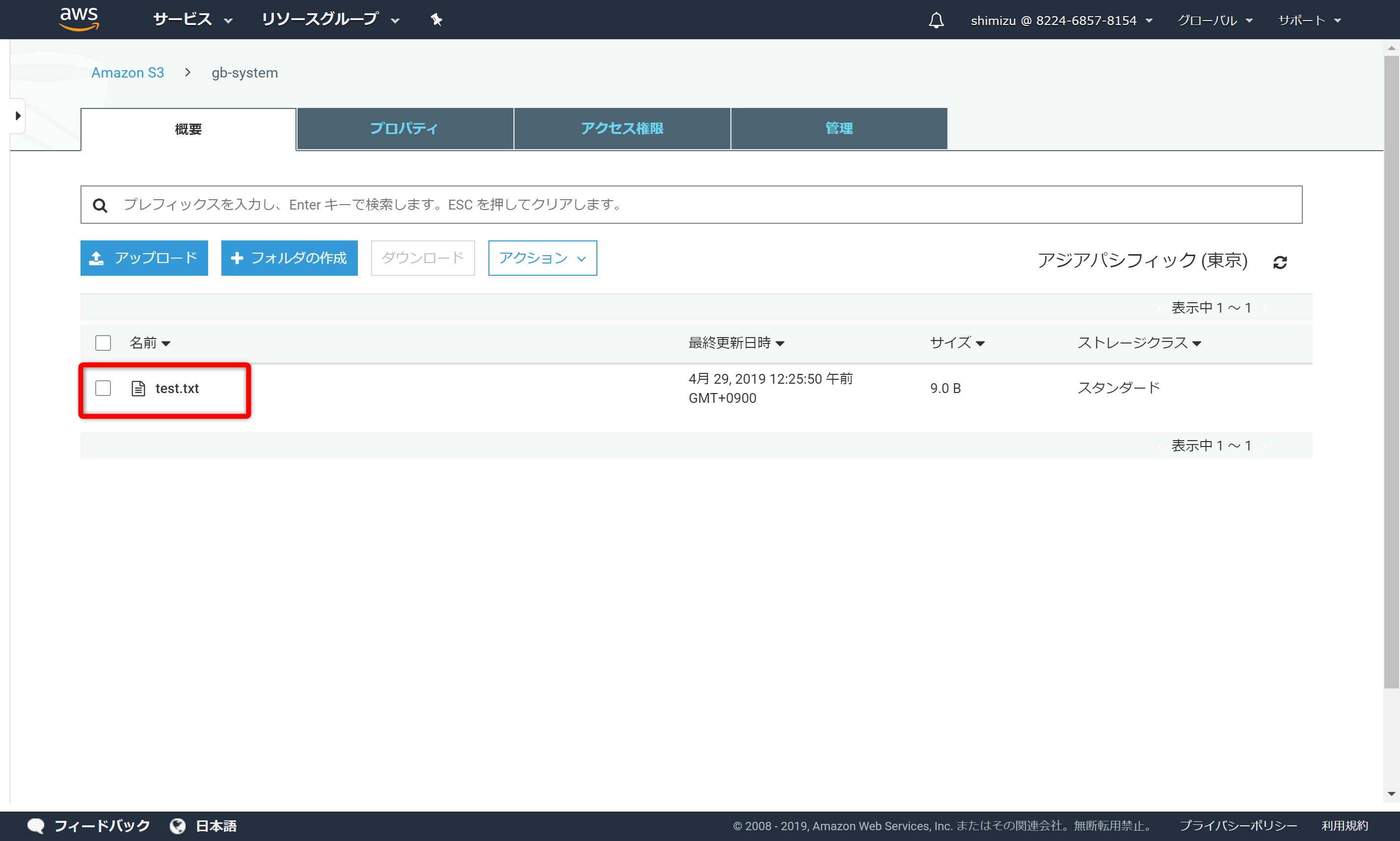
S3よりファイルを確認します。
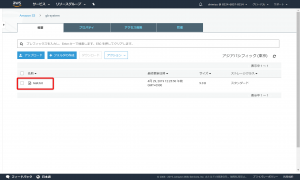
確かにS3にファイルが書き込まれました。ダウンロードしてファイルの内容を確認すると、「Hello S3」と記されています。自動マウント設定済みですので、予期しない再起動があった場合でも問題ありません。
まとめ
goofysを利用すると、EC2で用意した仮想インスタンスに簡単にS3をマウントすることができました。これで無制限にファイルを保存することができます。例えばサーバのログはどんどん溜まっていくので、S3に出力されるようにしておくと容量の心配がいらないですね。使いみちはいろいろと考えられるのでぜひ活用してみて下さい。
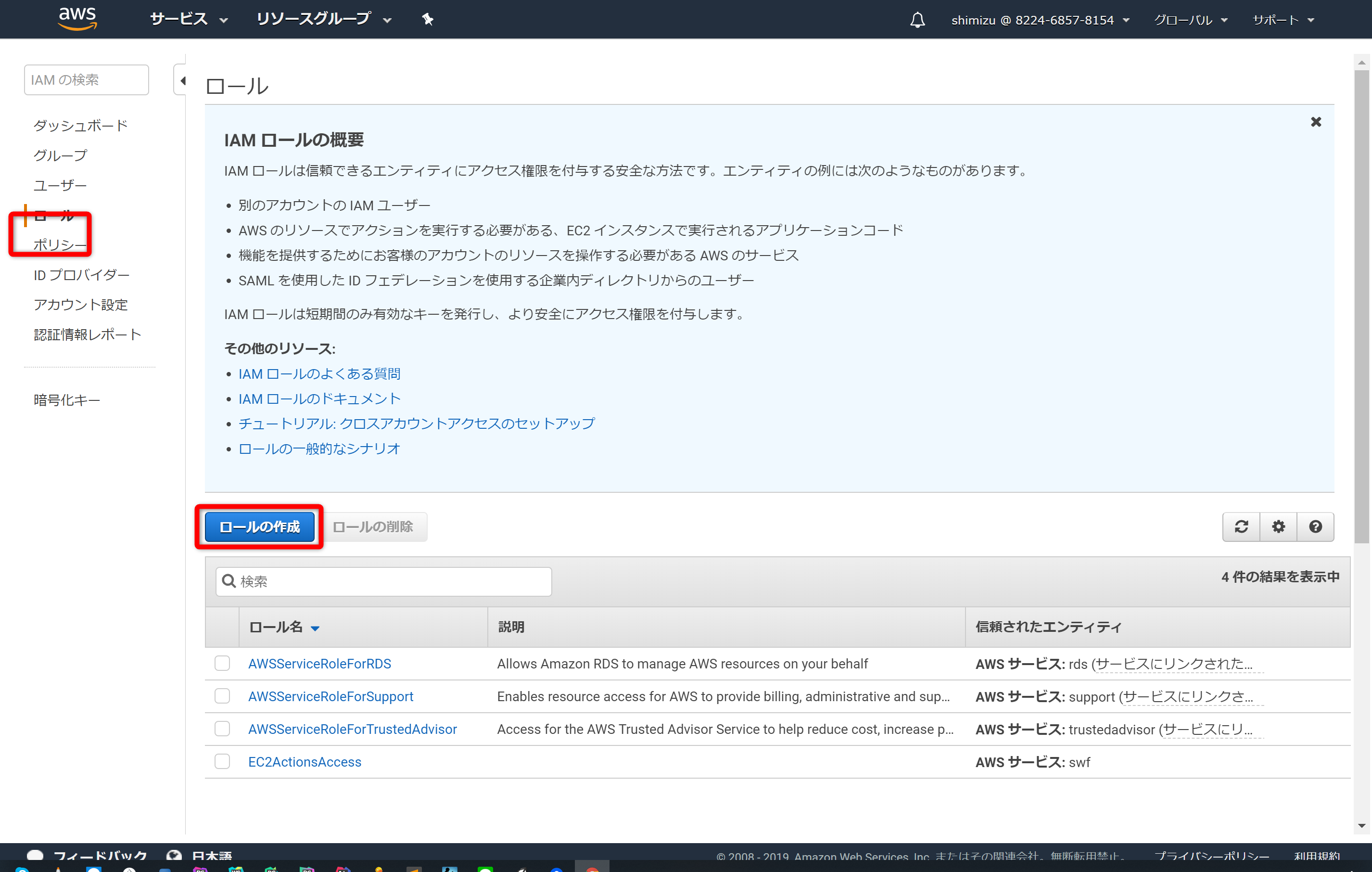 「EC2」を選択し、次のステップへ進みます。
「EC2」を選択し、次のステップへ進みます。
 「ポリシーのフィルタ」に「S3」と入力し「AmazonS3FullAccess」を探しチェックを入れます。そして次のステップへ進んで下さい。
「ポリシーのフィルタ」に「S3」と入力し「AmazonS3FullAccess」を探しチェックを入れます。そして次のステップへ進んで下さい。
 ここではロールの名前を「EC2_to_S3」としました。
ここではロールの名前を「EC2_to_S3」としました。
 念のため、立ち上げ直後はOSをupdateしておきましょう。
念のため、立ち上げ直後はOSをupdateしておきましょう。
 確かにS3にファイルが書き込まれました。ダウンロードしてファイルの内容を確認すると、「Hello S3」と記されています。自動マウント設定済みですので、予期しない再起動があった場合でも問題ありません。
確かにS3にファイルが書き込まれました。ダウンロードしてファイルの内容を確認すると、「Hello S3」と記されています。自動マウント設定済みですので、予期しない再起動があった場合でも問題ありません。
 2022.07.18 AWS CodeBuild で AWS S3 にアップロードする方法
2022.07.18 AWS CodeBuild で AWS S3 にアップロードする方法 2022.06.06 移動中でもモバイルからサーバ管理できる Mosh
2022.06.06 移動中でもモバイルからサーバ管理できる Mosh 2022.02.07 AWS EC2インスタンスバックアップの 2つの方法
2022.02.07 AWS EC2インスタンスバックアップの 2つの方法 2020.01.27 AWS EC2 Laravel6 構築 ~後編~
2020.01.27 AWS EC2 Laravel6 構築 ~後編~