PythonライブラリのBeautifulSoup4とrequestsを使い、ログイン先のHTMLソースを取得します。

環境
Pythonの実行環境が無い方は、「Colaboratory」での実行をおすすめします。
必要な情報
ログイン後のhtmlを取得する場合、
URLを叩く際に、Webサーバへ以下の情報を送る必要があります。
・クッキー情報
・POSTパラメータ(ログインID、パスワード、トークンなど)
渡す必要のあるPOSTパラメータは、ログイン画面のソースを見ることで判断できます。
<form method=”POST”>の中の、「name」属性があるタグの「value」属性の情報が必要となります。
<form method="POST" action="/login"> <input type="hidden" name="_token" value="06OM24DHZ02FjwLkjmOUoJF4lXa3ruLx0c"> <div>E-Mail Address <input name="email"></div> <div>Password <input name="password"></div> <div><button type="submit" class="btn btn-primary"> Login </button></div> </form>
または、ブラウザで通常のログインをする時に、デベロッパツールで確認することもできます。

プログラム実行
# ライブラリをインストール
pip install requests
pip install BeautifulSoup4
# モジュール読み込み
import requests
from bs4 import BeautifulSoup
# ログインページのURLから、BeautifulSoupオブジェクト作成
url = "https://sitepage.jp/login"
session = requests.session()
response = session.get(url)
bs = BeautifulSoup(response.text, 'html.parser')
# クッキーとトークンを取得
authenticity = bs.find(attrs={'name':'_token'}).get('value')
cookie = response.cookies
# ログイン情報
info = {
"_token": authenticity,
"email": "メールアドレス",
"password": "ログインパスワード",
}
# URLを叩き、htmlを表示
res = session.post(url, data=info, cookies=cookie)
print(res.text)
ログイン先のソースが表示されれば成功です。
BeautifulSoupでデータを整形して、便利な収集ツールを作成してみてください。
関連記事
 2018.10.28 これだけ押さえておけばSEO対策は万全「Lighthouse」
2018.10.28 これだけ押さえておけばSEO対策は万全「Lighthouse」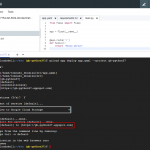 2018.05.06 Python 3.7 Flaskを利用したGoogle App Engine のチュートリアル
2018.05.06 Python 3.7 Flaskを利用したGoogle App Engine のチュートリアル 2019.01.20 GitHub Pagesを利用したサイト構築
2019.01.20 GitHub Pagesを利用したサイト構築 2022.06.06 移動中でもモバイルからサーバ管理できる Mosh
2022.06.06 移動中でもモバイルからサーバ管理できる Mosh 2019.05.26 無料で始めることができる天気情報取得API – OpenWeatherMap
2019.05.26 無料で始めることができる天気情報取得API – OpenWeatherMap